
Как быстро найти причины сбоев и предотвратить отказ сервисов? Рассказала команда GMonit
23.04.202517 апреля мы провели технический вебинар «Как расследовать ИТ-инциденты с GMonit — метрики сами подскажут ответ», в ходе которого обсудили, как определить источник и масштаб сбоев, выстроить непрерывное наблюдение за состоянием систем и минимизировать время простоя программ.
Юрий Махоткин, тимлид разработки GMonit, в рамках live demo разобрал кейс устранения инцидента в инфраструктуре с помощью observability платформы. Зрители трансляции получили практические рекомендации по оптимизации процессов и повышению устойчивости ПО. В рамках этой темы обсудили структуры «бабочки» и «рыбы» — визуальные и логические модели, которые помогают упорядочивать информацию о сбоях, выявлять корневые причины ошибок и выстраивать систему защиты от повторных нарушений.
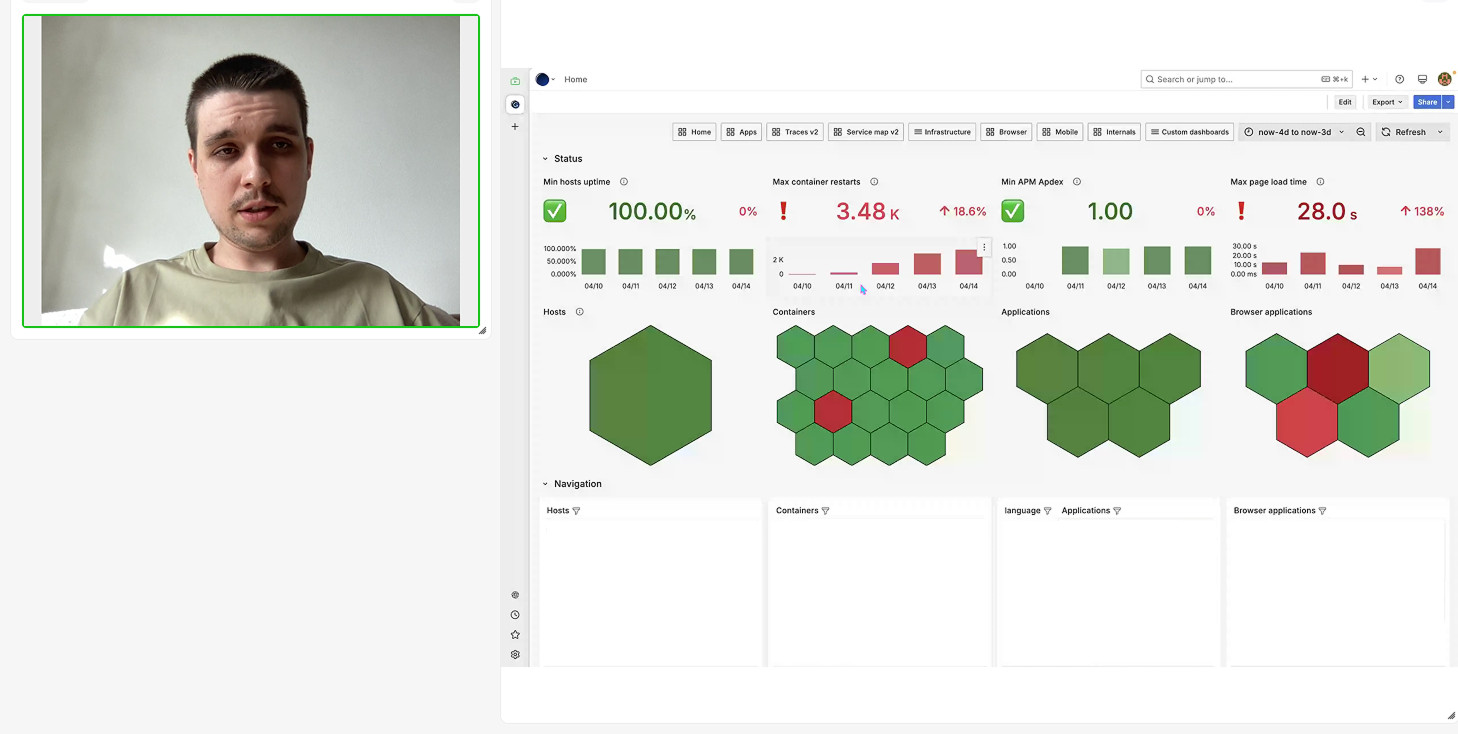
Спикер показал методику расследования инцидентов — от автоматического детектирования проблем через алерты до глубокого мониторинга с использованием данных телеметрии. Участники узнали, как эффективно идентифицировать источник ошибок. Также специалист продемонстрировал ключевые графики и метрики, отражающие поведение программ:
- время недоступности (downtime);
- график количества ошибок (error rate);
- среднее время отклика приложения (response time) на уровне транзакций и вызовов сервисов;
- метрики производительности (performance metrics);
- нагрузка на базу данных со стороны приложения (DB query rate/latency);
- пример трассировки (tracing) обработки конкретного запроса — для анализа цепочки вызовов и выявления узких мест.
В заключение Юрий рассказал про настройку полезного алертинга и детектирование аномалий с ИИ в GMonit. Благодаря методам Machine Learning бизнес может предсказывать потенциальные риски и заранее принимать меры для защиты критичных сервисов. После — спикер провел сессию вопросов и ответов.
Предлагаем к просмотру видеозапись выступления:
Источник: https://gmonit.ru/blog/it-incidents